このページに記載の情報は、2005 年にリリースした PowerGres Plus V2 を対象としています。PowerGres Plus V2 の販売はすでに終了しています。
PowerGres Plus の最新バージョンに関する情報は、製品紹介ページまたは PowerGres 体験記ページを参照してください。
前回は、Slony-Iを利用することで、マスタとなるデータベースの複製が簡単に作成できることをご紹介しました。
今回は、前回ご紹介したシステムを、大規模で実践的なシステムに拡張するために、pgpoolというツールを組み合わせてみます。pgpoolには、データベースへの接続をプーリングし、効率よく参照するための機能があります。これを使用することで、Slony-Iで複製されたデータベースの参照効率が向上します。
Slony-Iとpgpoolを組み合わせたシステムの構築には、いくつかのポイントがありますので、実例を交えてご紹介します。
これからご説明する「大規模参照システム」とは何かをご説明します。
最近では、小規模で始めた事業が、ヒット商品の出現やメディアで紹介されることで、一気に流行し、インターネット上でのアクセスが数十倍に増えることもめずらしくありません。アクセスが一気に増えた場合、顧客のデータ参照を停滞させることなく、ビジネス拡大を行うためにも、迅速、かつ簡単にシステムを増設することが重要です。
大規模参照システムとは、アクセスが一気に増えた場合に顧客に影響を与えず柔軟にシステムを拡張でき、かつ、顧客が効率よくデータを参照することができるシステムです。システムの拡張にはSlony-Iというレプリケーションソフトウェアを利用します。Slony-Iはチェーン方式と呼ばれる方式により、システムを簡単に増設できるレプリケーションソフトウェアです。
さらに、pgpoolというコネクションプールサーバを使用して、接続オーバヘッドを低減させ、システム全体のスループットを向上させます。
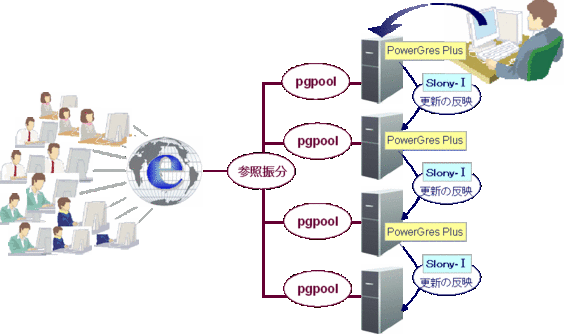
図 1: 大規模参照システム
今回利用するpgpoolについて簡単に説明します。
pgpoolはPostgreSQL専用のコネクションプールサーバです。例えば、PostgreSQLのクライアントがpgpoolに接続すると、初回はPostgreSQLへの接続が確立されます。クライアントの処理が終了してもPostgreSQLへの接続は切断されずそのまま残ります。次回、同じユーザ、データベースでpgpoolへの接続があった場合、前回使用した接続が再利用されます。アプリケーションサーバを利用したシステムでは異なるユーザで接続がする場合がありますので、pgpoolに接続するときには、なるべく同じユーザで接続するような考慮が必要となります。
この機能により、PostgreSQLサーバへの接続オーバヘッドを低減でき、システム全体のスループットを向上させることができます。
PowerGres PlusでもPostgreSQLと全く同じ手法で、pgpoolを使用することができます。
これからご説明する内容の、Slony-Iのサンプルスクリプトは、大規模参照ソリューション 第1回でご紹介したものと内容がほとんど同じで、違っているのはホスト名だけですので、そちらを修正してご利用ください。
本来は、4台、5台のマシンを使用したシステム構築をご紹介したいところなのですが、説明を簡単にするため、今回は2台のマシンを使用したシステムを構築します。実際にマシンを4台、5台と増やすことは、2台のマシン構成を応用することで簡単に行うことができます。
今回は、Server1という名前のサーバをマスタ、Server2という名前のサーバをスレーブとします。
pgpoolはコネクションプーリングサーバとして使用します。
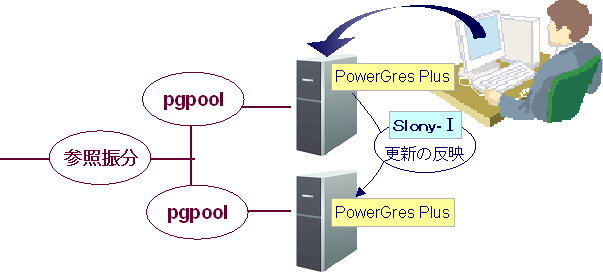
図 2: 構築するシステムの概要
前準備は、第1回と製品の入手方法、インストール、環境構築手順は、ほぼ同様で重なる部分もありますが、手順をおって説明するため、最初から説明します。
Slony-Iは、PostgreSQL用に作成されています。Slony-IをPowerGres Plusで使用するためには、PowerGres Plus V2.0でSlony-Iを使用するためのパッチとSlony-IでPowerGres Plusを使用するようにするパッチが必要になります。
PowerGres Plusのパッチは製品を購入していただく必要があります。 製品購入後、最新のパッチを適用してください。 パッチの適用方法については入手したパッチのREADMEをご覧ください。
購入につきましては、以下のURLより、ホームページ上部の[製品/サポート購入]をご覧ください。
今回はSlony-I 1.1.0を使用します。 ソースを圧縮したものをサンプル一覧にslony1-1.1.0.tarというファイルで提供しておりますのでご使用ください。
サンプル一覧 に、sl_1_1_0-esm-gs2.diff という名前で提供しておりますので、ご使用ください。
以下のURLより最新のpgpoolを取り出します。
https://pgfoundry.org/frs/download.php/899/pgpool-3.0.2.tar.gz
以下の手順で、Server1とServer2の両方にSlony-Iをインストールします。 入力するコマンドの詳細は、大規模参照ソリューション 第1回をご覧ください。
任意のディレクトリにslony1-1.1.0.tarを複写し、slony-Iのディレクトリを展開します。 展開が終わると、slony1-1.1.0というディレクトリが作成されます。
次に、slony1-1.1.0ディレクトリにsl_1_1_0-esm-gs2.diffファイルを複写し、パッチを適用します。
slony1-1.1.0のディレクトリに移動し、Slony-Iをビルドするための環境を構築します。オプションには、-with-pgconfigdir=/usr/local/pgsqlplus/binを指定します。
makeコマンドで、slony-Iをビルドします。
rootでSlony-Iをインストールします。
Slony-Iは、PowerGres Plusインストールディレクトリ配下のbinディレクトリにインストールされます。 /usr/local/pgsqlplus/binディレクトリを見てください。 以下のコマンドが増えているか確認してください。
slon は実際にレプリケーション処理を管理します。 slonik は、Slony-I のレプリケーションの構成を定義するスクリプトを処理するためのコマンドです。
Server1で、マスタデータベースを Administrator で定義します。 slmaster というデータベースを作成します。
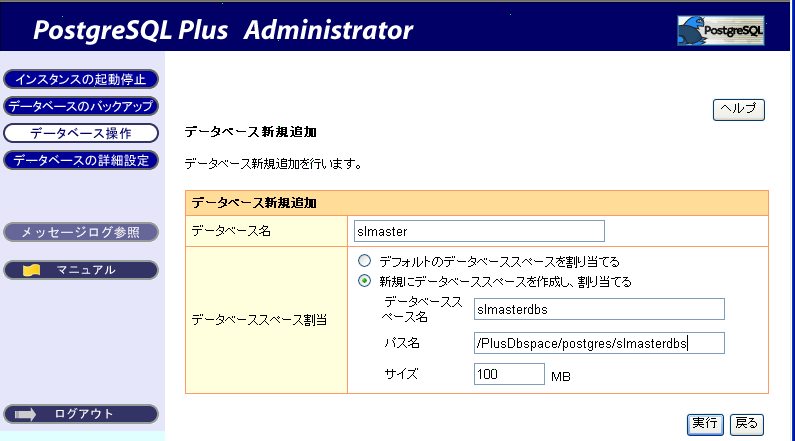
図 3: データベースの定義
同様にServer2で、スレーブデータベースを slslave という名前で作成します。
第1回同様にサンプル用の表table1を作成します。
これで、マスタデータベースの定義ができました。マスタデータベースに定義した内容をスレーブデータベースにも定義します。以下のようにpg_dumpコマンドと、psqlコマンドを使用して定義します。なお、マスタデータベース、および、スレーブデータベースの管理者は、postgresであるとします。
$ pg_dump -s slmaster | psql -h Server2 -U postgres slslave
これで、スレーブデータベースにもtable1が定義されました
第1回で使用したサンプルスクリプトslmaster.shの変数HOST1とHOST2を以下のように修正して、Server1で実行します。
スクリプトの実行が成功すると、マスタのデータベースにSlony-Iの管理テーブルが作成されます。以下のようなSQL文で確認できます。
slmaster=# SELECT nspname,relname FROM pg_class,pg_namespace WHERE relnamespace = pg_namespace.oid and nspname = '_slony_test1';
以下のようにサンプルスクリプトnode1.shの変数HOST1を変更し、実行して、マスタデータベースのslonデーモンを起動します。実行に成功するとそのままデーモンとして起動され、定期的にログ情報がターミナルに表示され続けます。
次に、Server2でターミナルを開いて、サンプルスクリプトnode2.shの変数HOST2を以下のように修正して、実行し、スレーブデータベースのslonデーモンを起動します。実行に成功すると、node1.shの実行と同様に定期的にログ情報がターミナルに表示され続けます。
第1回と同じように、マスタデータベースのtable1にデータを挿入してみます。
この時点ではまだ、スレーブデータベースにはデータはありません。
最後にサンプルスクリプトslslave.shの変数HOST1,HOST2を以下のように修正し、Server2で実行して、レプリケーションを開始します。このスクリプトは、スレーブデータベースのあるマシンで実行します。スクリプトの詳細は、Slony-Iのマニュアルをご覧ください。
スレーブデータベースのtable1の内容を見ると、マスタデータベースで挿入したデータが入力されています。
ダウンロードしたpgpoolをServer1、Server2にインストールし、環境を構築します。
以下の作業を行います。
Server1およびServer2で、任意のディレクトリで、ダウンロードしたpgpool-3.0.2.tar.gzを展開します。
$ tar zxvf pgpool-3.0.2.tar.gz
pgpool-3.0.2というフォルダが作成されるので、以下のようにコマンドを入力して構築をします。
$ cd pgpool-3.0.2 $ ./configure $ make
構築が正常終了したら、rootで以下のコマンドを入力して、pgpoolをインストールします。
# make install
インストールが正常に終了すると、以下のファイルがインストールされます。
/usr/local/etc/pgpool.conf.sampleを複写して、/usr/local/etc/pgpool.confを作成します。
今回は、初期値のまま起動しても問題ないので、そのまま起動してみましょう。
$ /usr/local/bin/pgpool
そして次にpgpool経由でServer1のslmasterに接続して、表の中身を見てみます。

図 4: pgpoolでデータベースに接続
参考のためにpgpool.confのポイントとなるオプションについて説明します。その他のオプションは、マニュアルおよび、pgool.confのコメントを参照してください。
pgpoolの配置には色々な方法があります。例えばWebサーバにpgpoolを1個だけ配置し、pgpoolを起動するときにそれぞれのサーバの設定を行ったpgpool.confをパラメタとして起動する方法。今回のようにそれぞれのデータベースシステムが起動しているサーバにpgpoolを配置する方法が考えられます。1台のサーバで複数のpgpoolを起動するのは負荷が高くなるので、今回はそれぞれのデータベースシステムが起動しているサーバにpgpoolを配置する方法をとります。
Server1と同様にpsqlコマンドで以下のようにしてServer2の情報が参照できます。
$ psql -p 9999 slslave
これで、Server1、Server2の間でSlony-Iを利用してレプリケーションをおこない、それぞれのデータベースへのコネクションプーリングを利用して参照する仕組みができました。せっかく複数用意したサーバもアクセスが1台に集中したのでは、ユーザの作業が待たされてしまいます。そこで、ユーザのデータ参照が効率良く行われるように参照の振分けを行います。
Server1、Server2への接続を切り替えるのは、サーバ名(サーバのIPアドレス)です。例えば、psqlコマンドでServer1、Server2にpgpoolを通して接続するには、以下のように記述します。
psql -h Server1 -p 9999 slmaster
psql -h Server2 -p 9999 slslave
参照の振分けを行うには、接続先を選択するためのロジックをアプリケーションに作成します。
例えば、依頼ごとに接続サーバを順番に切り替えるラウンドロビン方式でも十分な負荷分散を行うことができます。もう少し賢い制御を行うためには、Server1とServer2の最大接続数と、現在未使用の接続数を管理して、未使用の接続が多い方のサーバに接続するようにします。
また、サーバのスペックにあわせて、最大接続数を調整する必要もあるでしょう。例えば、Server2のハードウェアスペック(CPU数など)がServer1の2倍ある場合は、pgpool.confのmax_poolをServer1の2倍の値に設定して、システム全体としてのバランスを取ることも重要です。
大規模参照システムとして、オープンソフトウェアであるSlony-Iを使用したレプリケーション機能で構築したシステムに、さらにpgpoolというツールでコネクションプーリングを利用したシステムを構築するポイントをご紹介しました。今回は、1台のサーバ(1つのデータベース)に対して、1つのpgpoolを使用する方法をとりました。
サンプルスクリプトを利用すると、ご紹介したシステムが簡単に構築できますので、ぜひお試しください。
![]()