Chapter 7. 基本設計構造
7.1. PostgreSQL の基本設計構造の概念
本題に入る前に、先ず PostgreSQL の基本的な設計構造の概念を理解することが必要です。PostgreSQL の各部分がどのように相互作用するかを理解することによって、つぎの章がよりはっきりと理解できるます。データベース用語でいうと、PostgreSQL は「1 ユーザーに対し 1 プロセス」のクライアント/サーバーモデルを使用しています。PostgreSQL のセッションはつぎの協力しあう Unix プロセス(プログラム)により構成されます。
デーモン管理プロセス (postmaster)
ユーザーのフロントエンドアプリケーション(例:psql プログラム)
1 つ以上のバックエンドデータベースサーバー(postgres プロセスそのもの)
1 つの postmaster は、1 つのホスト上のデータベースの集まりを管理します。そのようなデータベースの集まりは(データベースの)クラスタと呼ばれます。クラスタの中のデータベースにアクセスしようとするフロントエンドアプリケーションは、(例えば libpq) インターフェイスライブラリを呼び出します。ライブラリはユーザーの要求をネットワークを介して postmaster (Figure 7-1(a)) に送ります。すると postmasterは、代わりに新しいバックエンドサーバープロセス(Figure 7-1(b)) を開始させます。
とフロントエンドプロセスの新しいサーバーへの接続。(Figure 7-1(c)) この時点以降フロントエンドプロセスとバックエンドサーバーは postmaster の介入無しに通信を行います。その結果フロントエンドとバックエンドプロセスが生成/消滅を繰り返すのに対して、postmaster は常に接続要求を待ちつつ稼働します。libpq ライブラリは 1 つのフロントエンドがバックエンドプロセスに対して複数の接続を行うことを許可します。とはいっても、それぞれのバックエンドプロセスはシングルスレッドプロセスで一度にひとつの問い合わせしか実行しません。ですからどのようなひとつのフロントエンドとバックエンド接続はシングルスレッドなのです。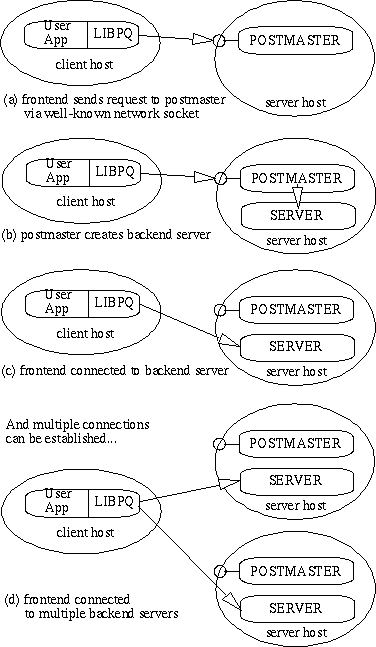
この基本設計構造が言外で意味していることは postmaster とバックエンドは常時同じマシン(データベースサーバー)上で稼働しているのに対し、フロントエンドアプリケーションはどこでも動かせるということです。クライアントマシン上でアクセス可能なファイルはデータベースサーバーマシン上ではアクセスできない(あるいは異なるパス名を使用しない限りアクセスできない)という理由があるのでこのことをよく覚えておいてください。
同時に知っておかなければならないことは postmaster と postgres サーバーは PostgreSQL の "スーパーユーザー" のユーザー ID で稼働します。PostgreSQL のスーパーユーザーはなにか特別のユーザー(例えば postgres) という名前のあるユーザー) でならない必要性は、たとえ多くのシステムでこのような方法を導入しているとしてもありません。さらに PostgreSQL スーパーユーザーは絶対に Unix のスーパーユーザーの root であってはいけません! 周りにある Unix システムに関するかぎり PostgreSQL のスーパーユーザーが通常の権限のないユーザーであることが最も安全です。いずれの場合もデータベースに関連したすべてのファイルはこの Postgres スーパーユーザーに属するべきです。