このページに記載の情報は、2005 年にリリースした PowerGres Plus V2 を対象としています。PowerGres Plus V2 の販売はすでに終了しています。
PowerGres Plus の最新バージョンに関する情報は、製品紹介ページまたは PowerGres 体験記ページを参照してください。
最近では、小規模で始めた事業が、ヒット商品の出現やメディアで紹介されることで、一気に流行し、インターネット上でのアクセスが数十倍に増えることもめずらしくありません。 そのような場合、その企業は、迅速、かつ簡単にシステムを増設しなくて はなりません。 Slony-I はチェーン方式と呼ばれる方式により、システムを簡単に増設できるレプリケーションソフトウェアです。
PowerGres Plus では、Slony-I を利用して、大規模なデータ参照を行うシステムを簡単に構築することができます。
初回となる今回は、Slony-I のご紹介と、PowerGres Plus で Slony-I を使用したシステムを構築するポイントをご紹介します。
最初にレプリケーションを利用したシステムの概要について説明します。
レプリケーションとは、データベースの複製を作成する機能です。 通常、複製の元になるデータベースを「マスタ (データベース)」、複製されたデータベースを「スレーブ (データベース)」と呼びます。 レプリケーションを実現するツールには商用のものもありますが、PostgreSQL で使用可能なものとして、Slony-I、pgpool、DBMirror などのオープンソースで提供されているものがあります。 今回は、マスタ 1 つに対し、複数のスレーブを定義可能な Slony-I でレプリケーションシステムを構築する準備や手順をご紹介します。 Slony-I では、図 1 のようにチェーン方式と呼ばれる方法でスレーブを追加できるので、システムを柔軟に拡張することができます。
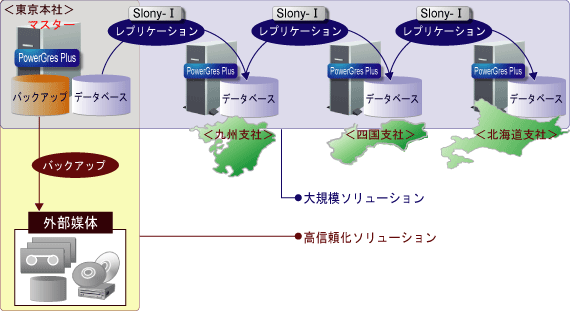
図 1: Slony-I によるシステム構成例
今回は、Slony-I を使用して、レプリケーションシステムを構築します。 Slony-I について概略を説明します。
Slony-I は、「非同期・シングルマスタ」方式のレプリケーションに分類されます。 この方式では、「実装がシンプルであること」、また「マスタとスレーブの間の回線が切断してもマスタ側への更新を止める必要がなく、後でまとめてスレーブ側に更新を反映することが可能である」というメリットがあります。 したがって、WAN 環境のように、ネットワーク接続が保証されないような環境にも適用することができます。 反面、1 つのマスタから一定間隔で更新データを 1 つまたは複数のスレーブに転送し、更新結果を反映するため、ある時刻を取るとマスタとスレーブの間では必ずしもデータベースの内容が一致しない場合がありますが、厳密な更新の同期を要求される業務は少ないため、それほど大きな問題とはいえないでしょう。
Slony-I で使用する用語を以下に説明します。 詳細は、日本 PostgreSQL ユーザ会が公開している Slony-I のマニュアルを参照してください。 日本 PostgreSQL ユーザ会の URL は以下です。
https://www.postgresql.jp/wg/jpugdoc/slony/1.1.0/adminguide/index.html
データベースインスタンスのセットで任意の名前をつけます。 レプリケーションは、このクラスタで指定されたデータベース間で行われます。
ノードは、レプリケーションが行われるデータベースです。
図 1 で説明すると、東京本社、九州支社、四国支社、北海道支社で行うレプリケーション全体がクラスタになります。 ノードは、各システムのレプリケーションの対象となるデータベースです。
今回は、初回ということで、練習の意味で 1 台のサーバでレプリケーションシステムを構築してみましょう。
Slony-I は、PostgreSQL 用に作成されています。 Slony-I を PowerGres Plus で使用するためには、PowerGres Plus 2.0 で Slony-I を使用するためのパッチと Slony-I で PowerGres Plus を使用するようにするパッチが必要になります。
PowerGres Plus のパッチは製品を購入していただく必要があります。 製品購入後、最新のパッチを適用してください。 パッチの適用方法については入手したパッチの README をご覧ください。
購入につきましては、ページ上部の 製品/サポート購入 をご覧ください。
今回は Slony-I 1.1.0 を使用します。 ソースを圧縮したものを サンプル一覧 に slony1-1.1.0.tar というファイルで提供しておりますのでご使用ください。
サンプル一覧 に、sl_1_1_0-esm-gs2.diff という名前で提供しておりますので、ご使用ください。
以下に Slony-I のインストール手順を説明します。
任意のディレクトリに slony1-1.1.0.tar を複写し、以下のようにコマンドを入力し、Slony-I のディレクトリを展開します。 展開が終わると、slony1-1.1.0 というディレクトリが作成されます。

図 2: Slony-I の展開
次に、slony1-1.1.0 ディレクトリに sl_1_1_0-esm-gs2.diff ファイルを複写し、以下のようにパッチを適用します。
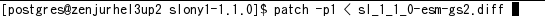
図 3: Slony-I へのパッチ適用
slony1-1.1.0 のディレクトリに移動し、以下のようにコマンドを入力し、Slony-I をビルドするための環境を構築します。 オプションには、-with-pgconfigdir=/usr/local/pgsqlplus/bin を指定します。

図 4: Slony-I のビルド環境の構成
以下のようにコマンドを入力し、Slony-I をビルドします。
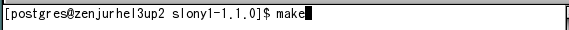
図 5: Slony-I のビルド
正常に終了すると以下のようにメッセージが表示されます。
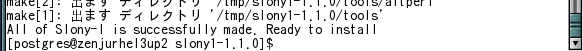
図 6: ビルドメッセージ
root で以下のようにコマンドを入力して Slony-I をインストールします。

図 7: Slony-I のインストール
インストールが正しく終了すると、以下のようなメッセージが表示されます。
図 8: インストールメッセージ
Slony-I は、PowerGres Plus インストールディレクトリ下の bin ディレクトリにインストールされます。 /usr/local/pgsqlplus/bin ディレクトリを見てください。 以下のコマンドが増えているか確認してください。
slon は実際にレプリケーション処理を管理します。 slonik は、Slony-I のレプリケーションの構成を定義するスクリプトを処理するためのコマンドです。
マスタデータベースを Administrator で定義します。 slmaster というデータベースを作成します。
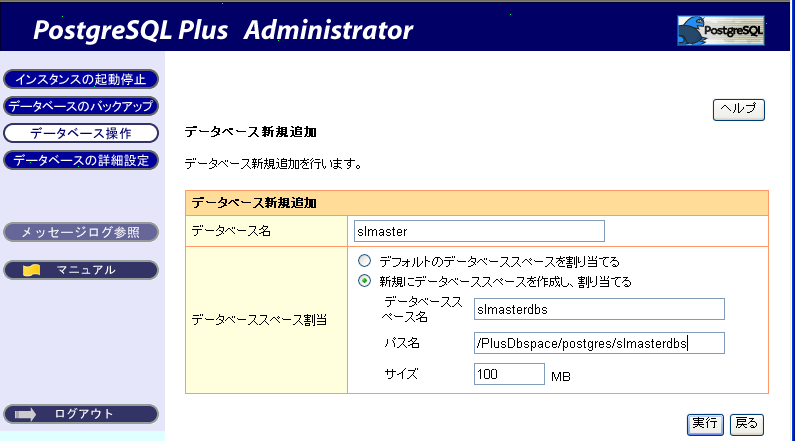
図 9: データベースの定義
同様にスレーブデータベースを slslave という名前で作成します。
今回は、1 台のマシンでシステムを構築するため、同一インスタンス内に、それぞれデータベースを作成しました。 2 台以上のマシンでシステムを構築する場合は、それぞれのマシン上に作成したインスタンス内にデータベースを作成します。
以下のような構成でマスタデータベースにサンプル用の表 table1 を作成します。

図 10: サンプル用表定義
また、Slony-I は plpgsql を使用するので、以下のコマンドを入力して、データベースに plpgsql インタフェースを定義します。
$ createlang plpgsql slmaster
これで、マスタデータベースの定義ができました。 マスタデータベースに定義した内容をスレーブデータベースにも定義します。 以下のように pg_dump コマンドと、psql コマンドを使用して定義します。

図 11: データベース定義の移行
これで、スレーブデータベースにも table1 が定義されました。
以下のようなスクリプトを作成して、Slony-I のレプリケーション環境を設定します。 サンプル一覧 に、slmaster.sh という名前で提供しておりますので、ご使用ください。
スクリプトで最初に定義している環境変数で、マスタとスレーブのデータベースや、データベースサーバを指定しています。 例えば、今回は 1 台でシステムを構築しているため、変数 HOST1 および HOST2 は両方とも localhost が指定されていますが、2 台のマシンを使用する場合は、HOST1 と HOST2 にそれぞれのデータベースサーバの名前 (アドレス) を設定します。 また、今回は複製する表が table1 だけですが、他にも表を追加する場合は、set add table スクリプトを追加することで、複製する表を追加することができます。 その他、詳細は Slony-I のマニュアルをご覧ください。
サンプルスクリプト slmaster.sh
#!/bin/sh CLUSTERNAME=slony_test1 DB1=slmaster DB2=slslave HOST1=localhost HOST2=localhost RUSER=postgres slonik << _EOF_ #今回使用するレプリケーションシステムが使用する名前空間の定義 cluster name=$CLUSTERNAME # クラスタのそれぞれのノードにノード1が接続するための定義 node 1 admin conninfo = 'dbname=$DB1 host=$HOST1 user=$RUSER'; node 2 admin conninfo = 'dbname=$DB2 host=$HOST2 user=$RUSER'; # 最初のノードを初期化します。1でなければなりません。この処理でこのレプ # ケーションシステム特有のスキーマ_$CLUSTERNAME(_slony_test1)を作成しま # す。 init cluster (id=1,comment = 'Master'); # Slony-Iはテーブルをセットに編成します。 # 以下のコマンドで全ての1つのtable1を含む1つのセットが作成されます。 create set(id=1, origin=1, comment='All tables'); set add table (set id=1, origin=1, id=1, fully qualified name='public.table1',comment='table1'); # 2番目のノード(スレーブ)を作成し、2つのノードがどのように接続し、また、 # どのように事象を監視するかを指示します。 store node (id=2, comment='Slave'); store path (server=1, client=2, conninfo='dbname=$DB1 host=$HOST1 user=$RUSER'); store path (server=2, client=1, conninfo='dbname=$DB2 host=$HOST2 user=$RUSER'); store listen (origin=1,provider=1,receiver=2); store listen (origin=2,provider=2,receiver=1); _EOF_
サンプルスクリプト slmaster.sh を以下のように実行します。
$ sh ./slmaster.sh
スクリプトの実行が成功すると、node1 のデータベースに Slony-I の管理テーブルが作成されます。 以下のような SQL 文で確認できます。
slmaster=# SELECT nspname,relname FROM pg_class,pg_namespace WHERE relnamespace = pg_namespace.oid and nspname = '_slony_test1';
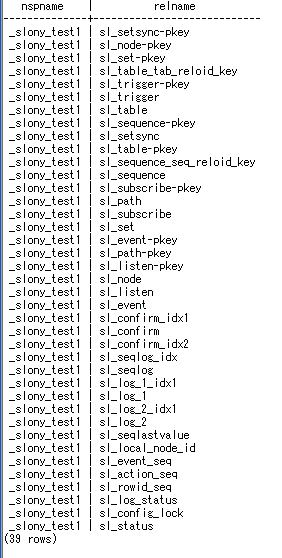
図 12: Slony-I 管理テーブル一覧
以下のようなサンプルスクリプト node1.sh を実行して、マスタデータベースの slon デーモンを起動します。 実行に成功するとそのままデーモンとして起動され、定期的にログ情報がターミナルに表示され続けます。 サンプル一覧 に、node1.sh というファイルで提供しておりますのでご使用ください。
#!/bin/sh CLUSTERNAME=slony_test1 DB1=slmaster RUSER=postgres HOST1=localhost slon $CLUSTERNAME "dbname=$DB1 user=$RUSER host=$HOST1"
次にもう 1 つターミナルを開いて、以下のようなサンプルスクリプト node2.sh を実行して、スレーブデータベースの slon デーモンを起動します。 実行に成功すると、node1.sh の実行と同様に定期的にログ情報がターミナルに表示され続けます。 サンプル一覧 に、node2.sh というファイルで提供しておりますのでご使用ください。
#!/bin/sh CLUSTERNAME=slony_test1 DB2=slmaster RUSER=postgres HOST2=localhost slon $CLUSTERNAME "dbname=$DB2 user=$RUSER host$HOST2"
では、マスタデータベースの table1 にデータを挿入してみましょう。
insert table1 values(1,'test1'); insert table1 values(2,'test2'); insert table1 values(3,'test3'); insert table1 values(4,'test4'); insert table1 values(5,'test5'); insert table1 values(6,'test6'); insert table1 values(7,'test7'); insert table1 values(8,'test8'); insert table1 values(9,'test9'); insert table1 values(10,'test10');
この時点ではまだ、スレーブデータベースにはデータはありません。

図 13: レプリケーション起動前のスレーブデータベースの表
最後に以下のようなサンプルスクリプトを実行して、レプリケーションを開始します。 このスクリプトは、スレーブデータベースのあるマシンで実行します。 スクリプトの詳細は、Slony-I のマニュアルをご覧ください。 サンプル一覧 に、slslave.sh という名前で提供しておりますので、ご使用ください。
サンプルスクリプト slslave.sh
#!/bin/sh CLUSTERNAME=slony_test1 DB1=slmaster DB2=slslave HOST1=localhost HOST2=localhost RUSER=postgres slonik << _EOF_ cluster name = $CLUSTERNAME; node 1 admin conninfo = 'dbname=$DB1 host=$HOST1 user=$RUSER'; node 2 admin conninfo = 'dbname=$DB2 host=$HOST2 user=$RUSER'; subscribe set(id=1, provider=1,receiver=2,forward=no); _EOF_
スレーブデータベースの table1 の内容を見てみましょう。 以下のようにデータが入力されています。

図 14: レプリケーション起動後のスレーブデータベースの表
今回は、オープンソフトウェアである、Slony-I を使用したレプリケーション機能による、簡単なレプリケーションシステムの構築方法をご紹介しました。
レプリケーションソフトウェアは、Slony-I の他にも、DBMirror や、pgpool などがあり、それらを組み合わせ、PowerGres Plus でシステムを構築することができます。
次回は、実際に複数のマシンを利用した環境構築のポイントをご紹介する予定です。
![]()